

소개
SQL Server는 관계형 데이터베이스(R-DB) 엔진으로 시작했지만 시대적 상황이나 요구에 맞추어 지속적으로 확장되고 있습니다. 예를 들어 XML, Hierarchical, Filestream, Spatial, Graph 심지어는 R/Python 머신 러닝에 이르기까지 참으로 다양합니다. 그리고 이제 살펴볼 내용은 빅데이터, OLAP, DW 와 같은 대용량 데이터 처리 환경에서 일반적인 집계, 통계, 분석용 함수들에 대한 이야기입니다.
Approximate Query Processing
일반적으로 알려진 Azure Synapse, pyspark, Snowflake 와 같은 DW 를 지원하는 시스템에서는 대부분 Approximate를 산출하는 함수를 지원하고 있습니다. 추측이지만 SQL Server에게도 이러한 함수들의 지원 요구가 많이 있었을 것입니다. SQL Server로 DW를 구성하거나 혹은 머신 러닝을 위한 분석용 쿼리 등에서 필요한 함수들로 기대할 수 있습니다.
대용량 데이터를 처리하는 과정에서 집계, 통계, 분석용 함수들을 사용하면 해당 크기만큼의 대량의 IO, 메모리를 소비하게 됩니다, 게다가 쿼리 최적화에 실패한 경우엔 메모리에서 데이터를 처리하지 못하고 tempdb Disk를 사용하면서 큰 부하를 유발할 수도 있습니다. 그런데 일반적인 통계 혹은 데이터 분석에서는 경향을 파악하고 이를 바탕으로 추론하는 것이 목적이므로 결과의 정확성보다는 응답성이나 확장성을 중요하게 보고 이를 위해 근사한 값과 일정 수준의 오차 범위를 허용하고 있습니다. 그렇다면 일반 함수보다 더 가볍고 부하가 적은 함수를 지원할 수도 있을겁니다.
이러한 용도와 목적으로 Approximate Query Processing에서 다양한 알고리즘(예. HyperLogLog, KLL Sketch 등)과 방법들이 지원되고 있고 Microsoft와 SQL Server에서도 2019 버전부터 COUNT(DISTINCT)에 대응하는 함수로 도입을 시작했으며 2022에서는 백분위 분포 함수에 대응하는 두 가지 함수를 도입했습니다.
- APPROX_COUNT_DISTINCT (2019)
- APPROX_PERCENTILE_CONT (2022)
- APPROX_PERCENTILE_DISC (2022)
SQL Server 2019의 COUNT(DISTINCT) vs. APPROX_COUNT_DISTINCT()
열의 유일값의 개수를 구할 때 COUNT(DISTINCT ) 함수를 사용하죠. 이에 대응해서 근사적인 값을 계산하는 것이 APPROX_COUNT_DISTINCT() 함수입니다. HyperLogLog 알고리즘을 사용하며 97% 확률과 최대 2% 오차률을 가지지만 대신에 훨씬 적은 메모리(혹은 Spill)를 사용할 수 있고 경우에 따라 빠른 응답 속도를 가질 수 있다고 소개하고 있습니다.
SQL Server 2022를 소개하는 것이 목적이니 이 함수에 대한 소개는 아래 참고를 보세요.
참고. 함수에 대한 기본 설명, 구문, 예제 등은 MS 문서 “APPROX_COUNT_DISTINCT“를 참조하세요.
PERCENTILE_CONT() / PERCENTILE_DISK() vs. APPROX_PERCENTILE_CONT() / APPROX_PERCENTILE_DISC()
SQL Server에서 제공하는 분포(Distribution) 함수 중에 백분위(예 0.5 는 일명 중위수 즉 50% 위치값) 값을 추출하는 두 가지 함수가 있습니다. 인수로 지정한 특정 분위수에 해당하는 값을 지정한 열에서 계산 또는 검색하고 반환합니다.
그 중 PERCENTILE_CONT()는 지정한 분위수의 해당하는 값을 계산으로 산출하고 반환합니다. 계산 값이므로 열에 있는 값 중에 동일한 값이 있을 수도 있고 없을 수도 있겠죠. PERCENTILE_DISC()는 해당 계산 값을 기준으로 실제 열 값을 찾아서 반환합니다. 계산 값과 같거나 작은 값을 반환하므로 동일한 값이 존재하지 않는다면 적은 값 중에 최대값을 찾는 것입니다.
테스트를 위해 아래 간단한 예제 코드를 사용하겠습니다.
참고. 함수에 대한 기본 설명, 구문, 예제 등은 MS 문서 “APPROX_PERCENTILE_CONT“와 “APPROX_PERCENTILE_DISC“를 참조하세요.
[코드-1] PERCENTILE_CONT() / PERCENTILE_DISK()를 사용한 예제
USE [WideWorldImporters];
SELECT
s.SupplierID, s.UnitPrice
, PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY s.UnitPrice)
OVER(PARTITION BY s.SupplierID) AS price_median_cont
, PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY s.UnitPrice)
OVER(PARTITION BY s.SupplierID)AS price_median_disc
FROM [Warehouse].[StockItems] AS s
GROUP BY s.SupplierID, s.UnitPrice
ORDER BY s.SupplierID, s.UnitPrice
[코드-2] APPROX_PERCENTILE_CONT() / APPROX_PERCENTILE_DISC()를 사용한 예제
SELECT
s.SupplierID, s.UnitPrice
, APPROX_PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY s.UnitPrice) AS price_median_cont
, APPROX_PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY CAST(s.UnitPrice AS money)) AS price_median_disc
FROM [Warehouse].[StockItems] AS s
GROUP BY s.SupplierID, s.UnitPrice
ORDER BY s.SupplierID, s.UnitPrice
리소스 사용량 비교
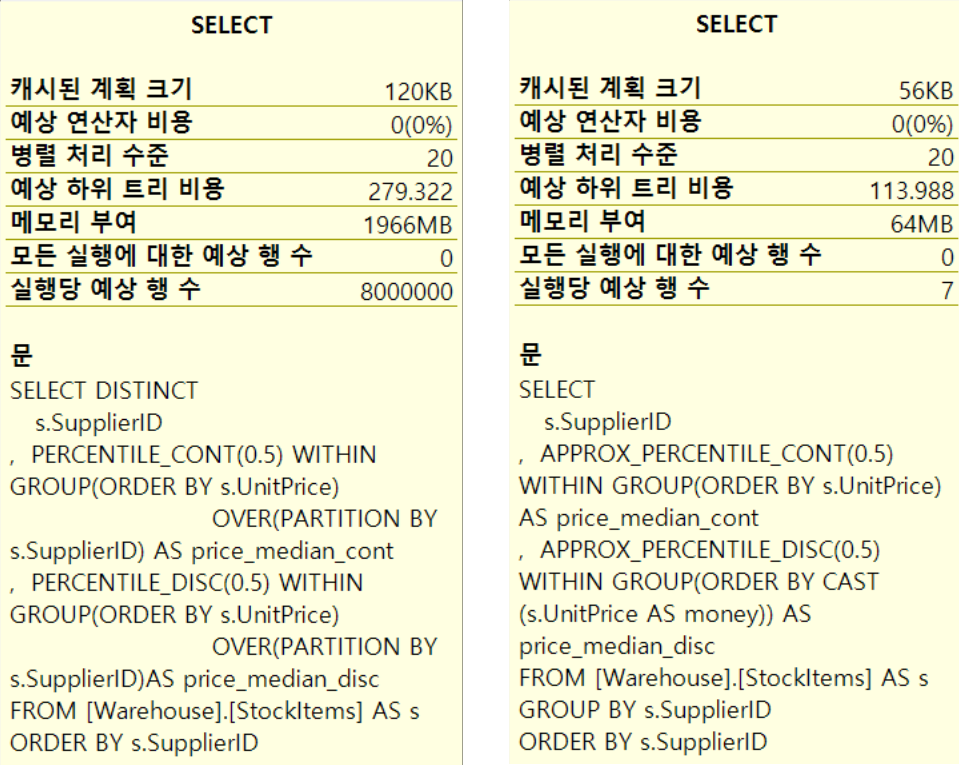
위 쿼리로 기존 함수(비 근사 함수)와 새로운 근사 함수의 요구되는 리소스(메모리 등) 사용량을 비교하기 위해서 각각 실행계획과 메모리 부여량을 비교해 봤습니다.
우선 아래 실행계획을 보면 기존 함수 대비 근사 함수가 훨씬 간단한 계획을 가지고 있으며 비용 측면에서도 71% 대 29%로 매우 적은 것을 알 수 있습니다.
[그림-1] 위 두 쿼리의 실행 계획 비교 (아래가 근사 함수에 해당)

두 쿼리에서 함수 연산을 위해 어느 정도의 메모리를 부여했는지 비교한 결과입니다. 기존 함수가 약 1,966MB이며 근사 함수가 64MB를 부여한 것으로 나옵니다(실제 사용된 크기는 차이가 있습니다). 대략적으로 봐도 메모리 부여(또는 사용)량에 큰 차이가 나는 것을 알 수 있으며 이것이 DB 서버의 리소스 부하나 성능에도 영향을 미칠 수 있을 겁니다.
[그림-2] 위 두 쿼리의 “메모리 부여” 량 비교 (오른 쪽이 근사 함수에 해당)
정리
작년부터 기업체 출강으로 SQL 교육 요청이 많아졌습니다, 총 120 명 정도의 인원을 대상으로 성능 좋은 쿼리 작성법(초/중급), 쿼리 튜닝(중/고급), DB 튜닝, 대용량 데이터 처리 등의 커리큘럼을 요청하십니다 그런데 특이한 부분이 SW개발이나 DB 운영 쪽이 아닌 일반 관리 업무(기획/영업/회계 등)와 AI와 같은 데이터 분석 업무에서도 참석을 많이 하신다는 겁니다. 가장 최근에 진행한 기업에서는 한 차수 40명 기준 80% 정도가 이러한 비 개발 직무 담당자여서 놀라기도 했습니다.
AI나 데이터 분석 파트에서야 당연히 필요한 부분이지만 비 개발 직무에서 조차도 이제는 사내에 저장된 데이터를 가지고 SQL로 직접 데이터를 추출, 정제, 분석하거나 시각화하는 일이 필요하고 요구되는 시대적 변화를 보여주는 것입니다.
이러한 근사 함수들이 실제 대용량 데이터의 집계, 통계, 분석 작업에서 성능 상 혹은 부하량 측면에서 얼마나 많이 도움이 될지는 앞으로 더 지켜봐야겠습니다. 개인적인 정보 채널과 짐작으로 미루어 이러한 함수들은 계속 추가될 것으로 보이니 SQL Server 사용자라면 적극적으로 활용해 보시길 권합니다.
모두 건강하세요.
김정선 드림

좋은 자료 감사합니다
고맙습니다 😀