

소개
지난 글 Memory Grant Feedback에 이어서 두 번째 Feedback 기능입니다. Query Optimizing에서 Cardinality Estimation이 무엇이고 어떤 역할을 하는지 이것이 쿼리 성능에 어떤 영향을 미치게 되는지 그리고 SQL Server 2022에서는 어떤 변화가 있는지를 소개하겠습니다.
참고. CE에 대한 전반적인 소개는 MS 문서 “Cardinality Estimation (SQLServer)“를 참조하세요.
참고. 아쉽지만 이 기능도 현재 Enterprise Edition에서 지원됩니다.
Cardinality Estimation(CE)
Cardinality
처음 듣는 분들은 Cardinality부터 이해가 필요하겠죠? 수학이나 통계학의 학문적인 설명은 제외하고 SQL을 기준으로 하면 행 (row)수를 말합니다 그래서 Table Cardinality라고 하면 테이블 행 수를 말하죠. SQL Server 또는 현재의 대부분의 RDBMS에서 동작하는 Query Optimizer는 쿼리의 Cost를 목표 값으로 최적화를하는데 이 때 이 Cost(비용)를 산정하는 기본 데이터가 바로 행 수입니다. Optimizing의 절차 중에 초기 단계에서 처리할 행 수를 미리 예측하고 이를 바탕으로 일련의 쿼리 최적화 과정을 거치게 됩니다. 따라서 행 수 예측의 정확도가 해당 쿼리 최적화의 결과 품질에 절대적인 영향을 미치게 됨을 알 수 있습니다.
Cardinality Estimation
문제는 Query Optimizing은 컴파일 단계에서 수행되는 작업이고 쿼리를 실행하기 전이므로 해당 시점의 정확한 행 수를 모른다는 것입니다. 예를 들어 아래와 같은 쿼리를 컴파일 할 때 OrderID 조건을 만족하는 행 수가 몇 건인지, ProductID 조건은 몇 건인지, 더 나아가 그 조건의 AND 결합된 최종 행 수는 몇 건인지를 실제 실행하기 전에는 정확히 알 수 없으므로 이를 사전에 알기 위해서 추정(Esitimation)을 하게 됩니다.
SELECT * FROM dbo.[Order Details] WHERE OrderID <= 10263 AND ProductID = 2

SQL Server Query Optimizer는 열 단위 Histogram 데이터와 수학적 모델을 이용해서 행 수를 추정합니다. Histogram를 이용하지 못하는 추정은 수식과 가정을 이용해서 계산하고 이를 일명 CE Model이라고 부릅니다.
CE Model과 DB 호환성 수준
SQL Server Query Optimizer는 사용자 입장에서 쿼리 성능의 차이를 보이는 SQL 엔진의 큰 변화를 준 시점(또는 해당 버전)이 몇 번 있습니다, 그 중 한 번이 버전 7(1998년 출시)이고 다음이 버전 2014입니다.
SQL Server는 버전 7에서 Query Optimizer를 새로 디자인합니다 따라서 이 때 CE Model(모델 7)에도 변화가 생기겠죠? 현재 우리가 사용하고 있는 Optimizing의 기반은 이 때 만들어진 후 현재까지 사용되고 있는 셈입니다. 그리고 버전 2014에 와서 다시 한 번 큰 변화를 가집니다 말 그대로 행 수 추정 결과가 달라진 것이죠. 실제론 2014 발표와 기업의 적용(업그레이드) 이후 CE Model의 변화로 인해 일부 쿼리에서의 성능 하락이 크게 이슈가 되었고 출시 후 바로 Service Pack 1이 나오기도 했었습니다.
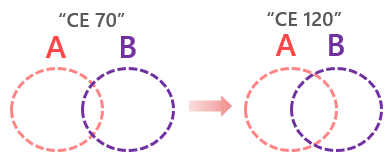
2014의 CE Model을 New CE(모델 120)라고 불렀고 이전 모델을 Old CE이라 지칭하며 그 둘을 비교하게 되었죠. 그리고 이 모델은 기본적으로 “DB 호환성 수준” 설정에 따라 영향을 받습니다 즉 업그레이드 후 DB 호환성 수준을 해당 버전으로 그대로 두느냐 아니면 이전 버전으로 하향 조정하는냐 따라서 어떤 버전의 CE를 사용하느냐를 결정하게 되는 것이죠.
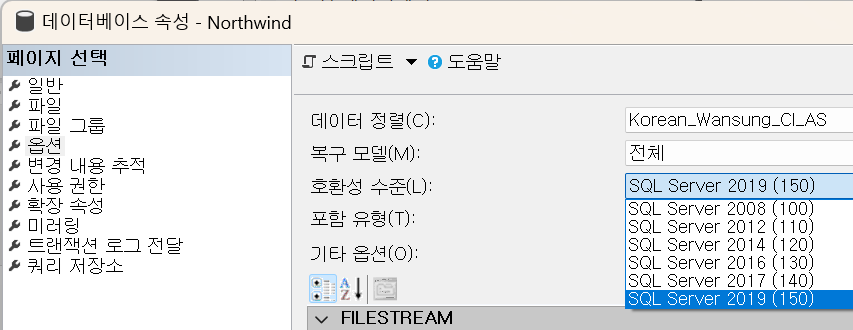
2016부터는 다시 New vs. Old CE 모델이라는 비교적 표현이 아니라 해당 SQL Server의 버전(130, 140, 150, 160)에 따라서 CE Model 버전을 표현하도록 변경되었습니다.
Cardinality Estimation Feedback 이란?
결국 SQL Server 버전 또는 DB 호환성 수준(그 외 여러가지 환경 설정)에 따라서 동일한 쿼리의 행 수 추정값이 달라지고 그것이 쿼리의 성능에도 중요한 영향을 미치게 되는 것입니다, 때로 더 빨리지기도 더 느려지기도 하는 것이죠 즉 경우에 따라 현재 버전의 CE가 더 좋은 결과를 내기도 하고 과거 버전의 CE가 더 좋은 결과를 내기도 한다는 것입니다.
실제로 많은 기업에서 업그레이드 후 성능 하락 이슈가 크게 대두되면 이를 회피하기 위해 DB 호환 수준을 낮추는 방법을 많이 이용했습니다. 이것이 세계적으로 중요한 이슈가 되다보니 Intelligent Query Processing의 하나로써 CE Feedback이라는 전략을 도입한 것이라 생각됩니다.
이전 글에서 Feedback의 개념을 설명한대로, 쿼리 실행 후 현재 CE 모델 상의 상당한 추정 오류가 있다고 판단되면 Query Optimizer가 다른 CE Model를 내부 절차에 따라 적용해 본 뒤 그 결과에 따라 성능이 개선된다면 해당 버전을 계속 사용하도록 지정하고 오히려 더 나빠지면 원래 버전으로 되돌리는 일련의 과정을 수행하는 방식입니다.
이 때 어떤 버전을 사용할 것인지와 실행 시마다 그 버전을 사용하도록 강제하기 위해서 Query Hint와 Query Store를 사용하게 됩니다. 따라서 쿼리의 행 수 추정 상의 분명한 문제가 있고 CE Feedback이 동작한다고 해서 바로 변화된 결과를 보이는 것이 아니라 일정 시간 또는 일정 수의 쿼리 실행 반복을 통해서 학습된 결과에 따라 달라질 수 있다는 것입니다.
정리
CE Feedback 도 기대되는 기능 중에 하나입니다. SQL Server 사용자가 쿼리 단위로 좋은 CE 모델을 찾아서 일일이 지정할 필요 없이 자동으로 처리해 줄 수 있다는 의도니까요, 물론 실제로 실무에서 어떤 결과를 만들게 될지는 앞으로 지켜봐야겠습니다.
마지막으로 SQL Server 2022의 Cumulative Update에는 Feedback 관련 기능 들에 대한 패치들도 적용되어 있으므로(버그도 잡고 기능도 개선하고 있다는 것이죠) 업그레이드 시 가급적 최신 CU를 적용해서 사용하시기 바랍니다.
모두 건강하세요.
김정선 드림
