

소개
개인적으로 수집한 마이크로소프트 자료에 의하면 Columnstore Index 관련 SQL Server 2022의 새로운 기능으로 몇 가지를 소개하고 있습니다만 다른 주제들은 새로운 기능이 맞는지 애매하거나 테스트 가능한 구체적인 자료가 없는 관계로 생략하고 가장 크고 중요한 변화인 정렬(Sort) 지원 Clustered Columnstore Index를 소개하겠습니다.
혹시 Columnstore Index를 모르신다면, 아래 MS 링크 문서를 참조하세요.
참고 자료
Ordered Clustered Columnstore Index(이하 CCI) 지원
Clustered Columnstore Index가 초기 생성 또는 저장될 때 일반적으로 정렬이 되지 않은 상태일 확률이 높고 그런 경우 행 그룹(세그먼트)의 범위(최소~최대)를 정확히 구분할 수 없으므로 조건을 만족하는 특정 행 그룹만 접근하고 다른 행 그룹은 제외하는 동작, 일명 “Skip Segment ” 처리가 이상적으로 동작하기 어려울 것입니다.
위와 같은 이유로 이전에는 필요 시 CCI를 생성하기 전에 테이블에 Clustered Index (+MAXDOP 1)를 미리 생성해서 데이터를 정렬시킨 상태로 그 위에 CCI를 생성하는 방법을 활용하기도 했습니다.
SQL Server에서 “Soft Sort“라는 개념을 지원하지만 완전한 Sort를 보장하지는 않는다고 합니다. 이제 2022 버전에서 Sort된 Clustered Columnstore Index를 지원하기 시작했습니다 그러나 개인적인 테스트 결과로는 고려할 특이점도 보였습니다.
우선 아래 새로 추가된 구문입니다, CREATE .. INDEX 문에 ORDER (column, …) 절이 보입니다. Sort하는 기준 열(들)을 지정하는 부분입니다. 구문에 대한 자세한 소개는 위 MS 두 번째 자료를 참고하세요.
CREATE CLUSTERED COLUMNSTORE INDEX index_name
ON { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ORDER (column [ , …n ] ) ]
[ WITH ( DROP_EXISTING = { ON | OFF } ) ] — default is OFF
[;]
그럼 간단하게 Clustered Columnstore Index를 1) 옵션에 따라 다르게 만들고, 2) 행 그룹 상태를 확인한 뒤에, 3) 쿼리 실행 시 동작과 성능 차이를 비교해 보겠습니다. 우선 Index 생성 옵션은 아래 3가지로 다르게 만들었습니다.
비교를 위해 매번 Table을 새로 생성한 뒤에 CCI를 생성했습니다.- ORDER() 를 지정하지 않은 기존의 일반 CCI (MAXDOP 8)
- ORDER(OrderDate) + MAXDOP 8 로 생성한 CCI
- ORDER(OrderDate) + MAXDOP 1 로 생성한 CCI
[코드-1] ORDER()를 지정하지 않은 기존의 일반 CCI
CREATE CLUSTERED COLUMNSTORE INDEX CCI_factOrders ON dbo.factOrders WITH ( MAXDOP = 8 )
[코드-2] ORDER(OrderDate) + MAXDOP(8 or 1) 로 생성한 CCI
CREATE CLUSTERED COLUMNSTORE INDEX CCI_factOrders ON dbo.factOrders ORDER (OrderDate) WITH ( MAXDOP = 8 -- 그리고 1 )
[코드-3] OrderDate로 검색하는 쿼리, 뒤에서 I/O 및 실행계획을 검토할 예정
-- IO 및 실행 계획 확인 SET STATISTICS IO ON; SELECT o.ORDERKEY, o.ORDERDATE, o.CUSTKEY FROM dbo.factOrders AS o WHERE o.OrderDate = '1998-05-29';
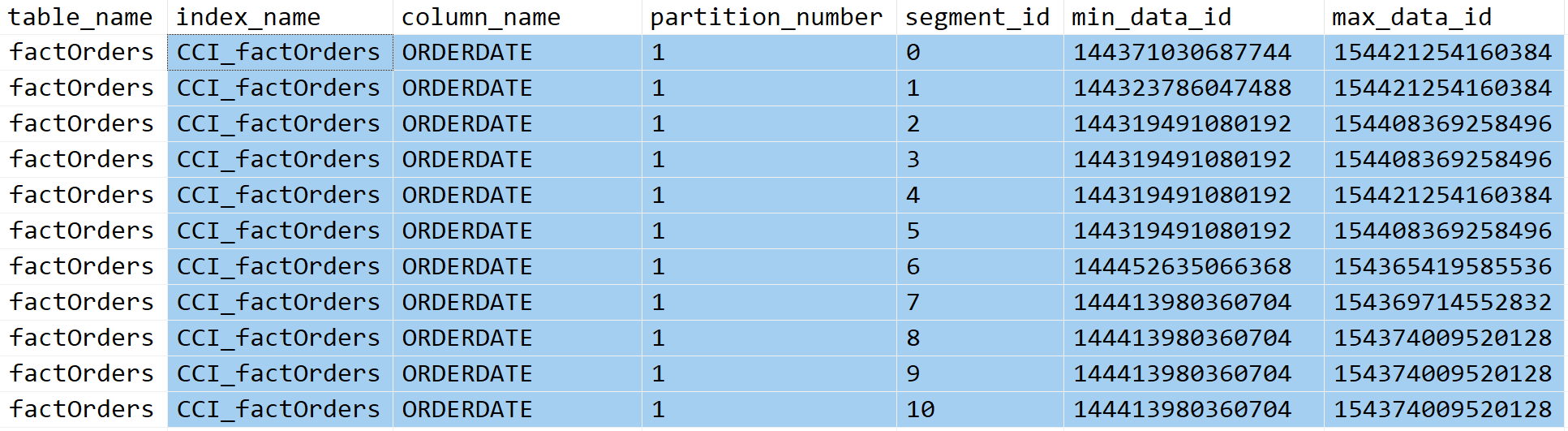
1. 디폴트(Non-Ordered)에서 행-그룹 상태 및 쿼리 성능
[그림-1] CCI 생성 후 행 그룹의 Min-Max 분포입니다.
각 segment_id의 min-max id 분포를 볼 수 있습니다.
[쿼리 실행 결과] SET STATISTICS IO ON로 쿼리 출력 메시지 확인
몇 개의 세그먼트를 읽고, 몇 개를 건너뛰었(skip)는지 볼 수 있습니다.
테이블 ‘factOrders’. 검색 횟수 1, 논리적 읽기 0, 물리적 읽기 0, 페이지 서버 읽기 0, 미리 읽기 0, 페이지 서버 미리 읽기 0, lob 논리적 읽기 8563, lob 물리적 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 24919, lob 페이지 서버 미리 읽기 0.
‘factOrders‘ 테이블에서 세그먼트가 11을(를) 읽고 2을(를) 건너뛰었습니다.
[그림-2] 쿼리 실행 계획
실행 계획 속성 중 “모든 실행에 대한 실제 행 수”와 “실제 일괄 처리 수”를 세 가지 경우로 비교해볼 수 있습니다.

2. Ordered + MAXDOP 8에서 행-그룹 상태 및 쿼리 성능
[그림-3] CCI 생성 후 행 그룹의 Min-Max 분포입니다. 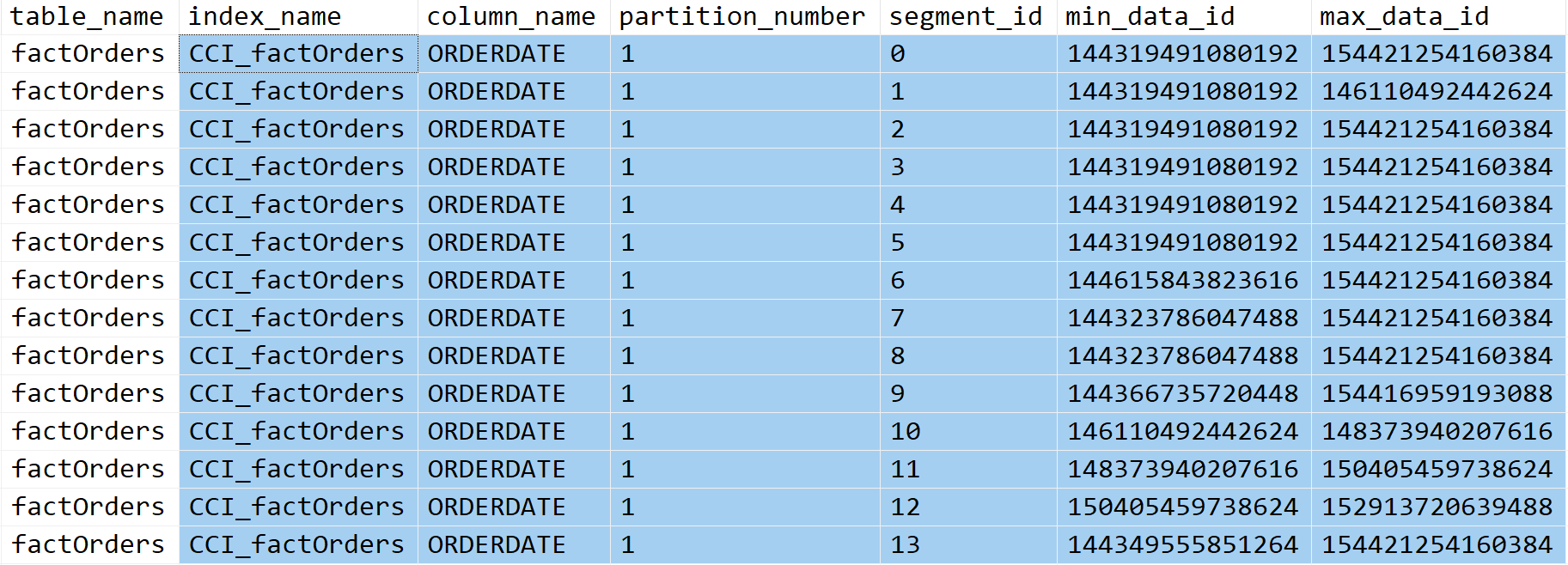
[쿼리 실행 결과] SET STATISTICS IO ON로 쿼리 출력 메시지 확인
테이블 ‘factOrders’. 검색 횟수 1, 논리적 읽기 0, 물리적 읽기 0, 페이지 서버 읽기 0, 미리 읽기 0, 페이지 서버 미리 읽기 0, lob 논리적 읽기 2488, lob 물리적 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 0, lob 페이지 서버 미리 읽기 0.
‘factOrders‘ 테이블에서 세그먼트가 7을(를) 읽고 8을(를) 건너뛰었습니다.
[그림-4] 쿼리 실행 계획

3. Ordered + MAXDOP 1에서 행-그룹 상태 및 쿼리 성능
[그림-5] CCI 생성 후 행 그룹의 Min-Max 분포입니다. 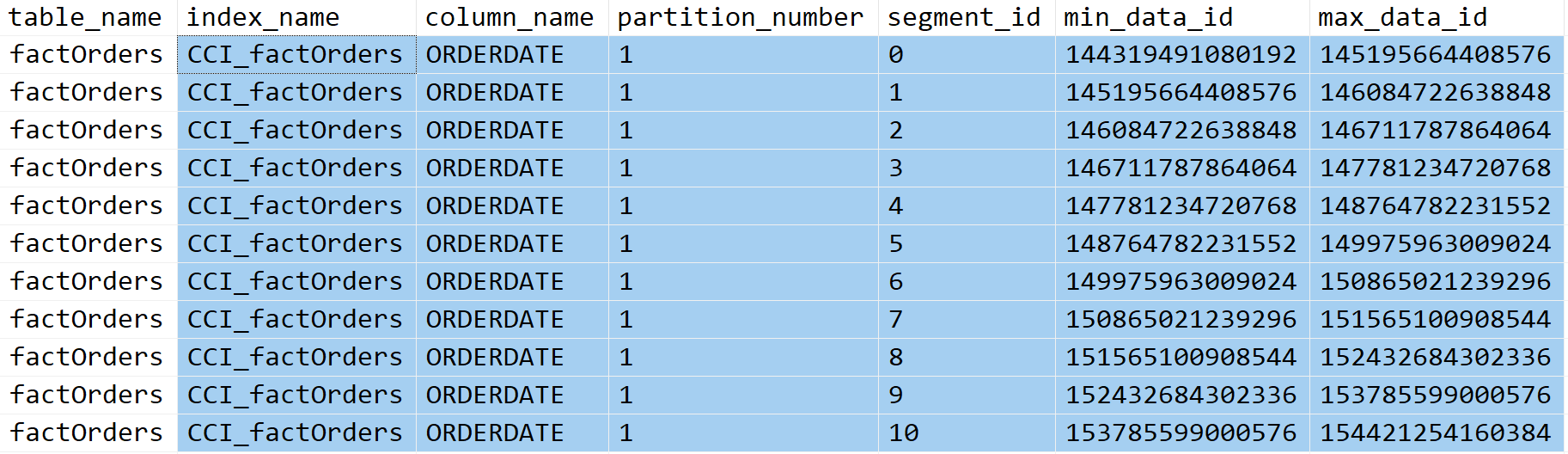
[쿼리 실행 결과] SET STATISTICS IO ON로 쿼리 출력 메시지 확인
테이블 ‘factOrders’. 검색 횟수 1, 논리적 읽기 0, 물리적 읽기 0, 페이지 서버 읽기 0, 미리 읽기 0, 페이지 서버 미리 읽기 0, lob 논리적 읽기 167, lob 물리적 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 0, lob 페이지 서버 미리 읽기 0.
‘factOrders‘ 테이블에서 세그먼트가 1을(를) 읽고 10을(를) 건너뛰었습니다.
[그림-6] 쿼리 실행 계획

정리
문서와는 달리 실제로 정렬된 데이터 구성과 세그먼트 제외를 제대로 처리하려면 (이전처럼) MAXDOP 1을 사용해야 함을 볼 수 있습니다.
SQL Server의 기능 중 현장에서 사용하는 것을 보기가 거의 어려운 몇 가지 대표적인 기능 중에 하나가 Columnstore Index이고 그것이 참으로 안타까워 오래 전부터 강의나 세미나 등에서 열심히 전파를 했었습니다 물론 지금도 여전히 그렇습니다^^
이 동작은 SQL Server 2022뿐만 아니라 Azure Synapse Analytics, Parallel Data Warehouse 등에서도 다루는 것으로 보입니다, 오래 전부터 DW 시장이 커지고 있고 SQL Server 개발팀에서도 지속적으로 업데이트하는 것으로 보아 계속 관심을 가지고 실무자 분들께 Columnstore Index를 소개하겠습니다. 혹시 모르셨다면 관심이 가져보시길 권합니다.
모두 즐거운 SQL하세요.
김정선 드림
