

소개
SQL Server Query Optimizer의 새로운 진보를 나타내는 것이 2017부터 적용된 “Intelligent Query Processing(IQP) and Database“, 그 중심에 있는 기능 이 “Adaptive Query Processing“이라 생각합니다. “Adaptive” 라는 영어를 조금 더 과장하면 아마도 “Auto Tuning”이라고 표현할 수 있는 범위에 들어간다고도 생각되어지네요.
이제부터 IQP의 세부 기능들을 하나씩 소개하겠습니다. 그 첫 번째가 “Memory Grant Feedback“입니다.
참고. Feedback 관련 기능에 대한 전반적인 소개는 MS 문서 “Query processing feedback features“를 참조하세요.
참고. 이 기능은 현재 Enterprise Edition에서 지원됩니다.
(Query) Memory Grant
기본적으로 쿼리는 초기 컴파일 단계와 이후 실행 단계에서 각각 필요한 메모리를 할당받아서 사용합니다. 그 중 실행 단계에서 필요한 메모리를 받는 것을 “Memory Grant” 라고 표현합니다. 주로 쿼리 실행 중에 Sort, Hash, Spool 과 같은 연산이 포함되는 경우 중간 데이터의 저장소 용도로 할당 받아 사용하는 것이죠. 해당 메모리를 “쿼리 실행 메모리”라고 부르며 SQL Server 메모리 구성 요소 중 한 부분을 차지합니다.
언급한 연산들은 쿼리에서 처리하는 데이터 양에 따라서 때로는 0 혹은 아주 작은 크기로 때로는 수 ~ 수십 GB 이상의 대용량 크기를 사용하기도 하며 이것이 쿼리 성능이나 DB 서버의 성능 및 안정성에 큰 영향을 끼치기도 합니다.
참고. (Query) Memory Grant 와 쿼리 성능 이슈에 대해서 MS 문서 “Troubleshoot slow performance or low memory issues caused by memory grants in SQL Server“를 참조하세요.
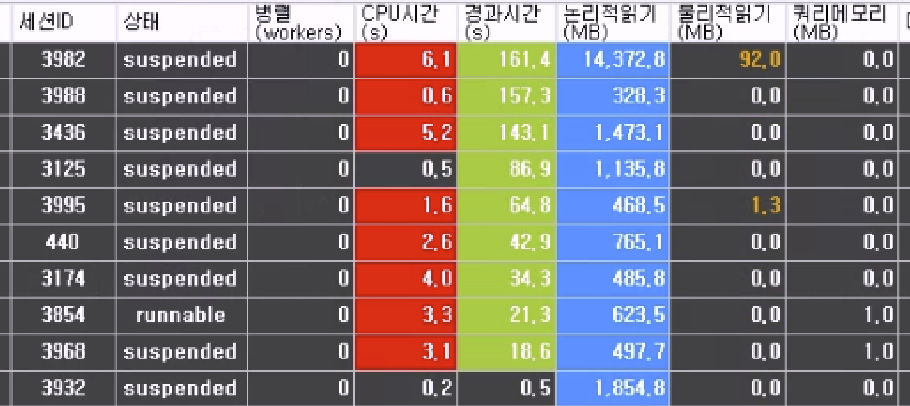
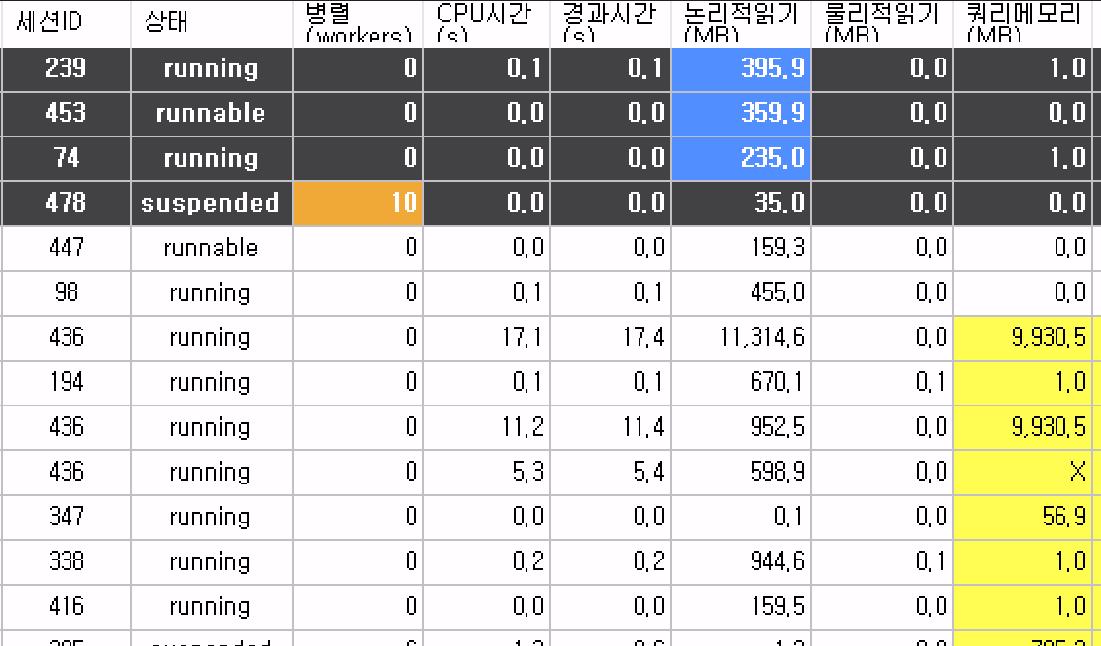
아래 실제 사례를 보면, 서로 다른 두 사이트의 SQL Server에서 쿼리가 사용하는 실행 메모리 크기를 비교해 볼 수 있습니다. 참고. 아래 이미지는 SQLBigEyes Professional 에서 캡처되었습니다, 해상도 낮은 점 양해 바랍니다.
[그림. 사례-A] 이 사이트의 고부하 쿼리들에서는 “쿼리메모리(MB)” 양이 대체로 매우 작음을 볼 수 있습니다. (Grid의 행 하나가 쿼리-세션 하나에 해당)
[그림. 사례-B] 이 사이트의 쿼리들은 “쿼리메모리(MB)”가 9,930MB 이상을 소비하는 경우를 자주 볼 수 있습니다.
Memory Grant Feedback(MGF) 이란?
[Feedback의 개인적 해석]
“Adaptive Query Processing”에서 Feedback이라는 단어가 포함되는 기능들이 몇 가지 있습니다(쿼리 실행 메모리, 병렬쿼리에서 CPU 수, 행 수 추정). 여기서 Feedback의 의미를 이해하면 이후 내용 해석에 도움이 될 수 있어서 저의 해석을 첨부합니다.
일반적으로 Query Optimizing은 쿼리 컴파일/최적화 단계에서 수행되죠, 다시 말해 쿼리를 실행하기 전 단계의 튜닝 작업입니다, 반면에 Feedback은 쿼리 실행 시 사용한 실행계획에서 특정 성능 이슈가 발견되면 다음 실행 시 이를 보정하도록 기존 실행 계획을 변경하거나 조정하는 방식 즉 일종의 후 보정 또는 사후 쿼리 튜닝 접근 방식이라 표현할 수 있겠습니다.
그럼 쿼리 실행 메모리의 크기는 언제 어떻게 산출되고 사용될까? Query Optimizing 시에 추정된 행의 수와 열의 크기를 계산해서 이를 기반으로 메모리 크기를 추정하고 요청합니다. 동시에 여러 개의 쿼리가 실행될 수 있기때문에 총 쿼리 실행 메모리는 SQL Server 구성 옵션으로 지정한 Max Memory에서 일정 비율(보통 70%)로 제한되며 특정 고부하 쿼리 하나가 그 메모리 전체를 점유하는 것을 방지하기 위해 다시 또 일정 비율(보통 25%)로 제한됩니다.
여기서 여러가지 문제(실제론 기술적 한계이지 않을까?)가 발생할 수 있는데 그 중 한 가지가 바로 메모리 크기 추정의 부정확성과 실행 계획 재사용에 따른 부작용 부분입니다. 아래 그림의 실제 사례를 통해서 살펴보겠습니다, 쿼리 메모리 크기 산출에 사용되는 행 수와 열의 크기는 추정과 계산에 의한 값이므로 실제 값과의 편차가 크게 발생하면(추정 오차) 결국 실제 필요한 메모리보다 더 많이 할당되거나 더 적게 할당될 수 있습니다. 더 많이 할당되면(그림에서 1번의 경고를 보면 “ExcessiveGrant“가 언급됨, 부여된 것은 약 46GB이지만 사용한 것은 6432KB) 메모리를 불필요하게 낭비하는 것이고 더 적게 할당되면 실제 메모리가 아니라 tempdb 즉 디스크에서 Sort와 같은 작업을 할 수 있게 되고 이 또한 부하를 일으킬 수 있습니다.
[그림. 사례 – SQL Server 2019에서 Memory Grant Feedback 동작]
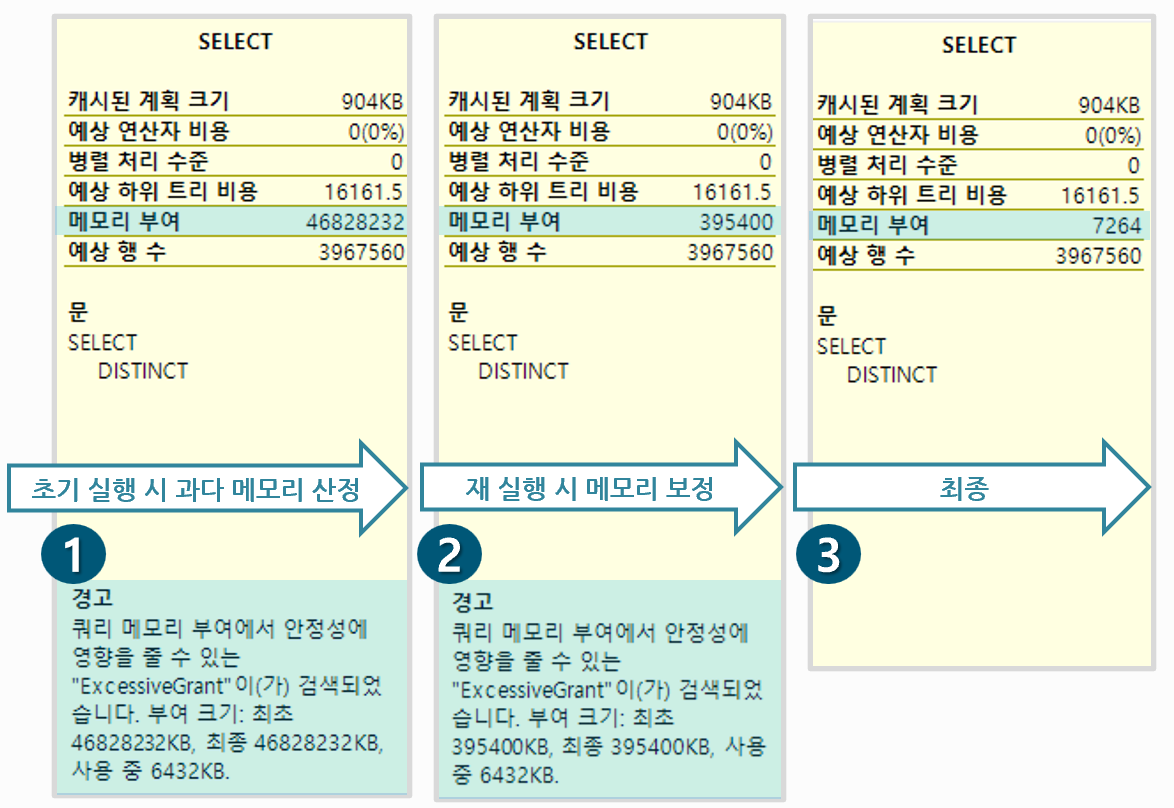
SQL Server 2017에서 처음 도입된 Memory Grant Feedback은 이러한 부작용을 완화시키거나 해결하는데 도움을 줍니다. 그림에서 2번을 참조하면 같은 쿼리가 두 번째 호출될 때 처음 실행 시 부여된 메모리(약 46GB)에서 395MB로 줄어든 것을 볼 수 있습니다. 그리고 세 번째 다시 호출될 때는 약 7264KB로 실제로 사용된 6432KB에 수렴하고 더 이상 경고가 발생하지 않습니다. 이것이 바로 Feedback의 동작 방식입니다, 후 보정 방식이라고 제가 표현한 이유를 공감하실겁니다.
SQL Server 2022에서 Memory Grant Feedback(MGF)
Feedback 방식 그리고 Memory Grant Feedback이 실무에 적용되면서 또 다른 이슈와 필요 사항이 발생합니다. 그 이슈에 대한 해결책으로써 SQL Server 2022에 확장된 버전의 MGF가 지원됩니다. 그 중 하나는 실행 계획이 Cache에서 제거되는 경우 원 문제가 재발된다는 점 또하나는 쿼리 실행 시마다 이전과 다른 행 수의 큰 차이(예. 1000건 vs. 1백만건)가 발생하는 경우 이전에 조정한 메모리 크기가 맞지 않은 상황이 반복된다는 것입니다.
참고. 아래 두 가지 동작에 대한 MS 문서 “Query processing feedback features“에 “Memory grant feedback” 부분을 보면 이해에 도움이 되는 이미지들을 함께 참조할 수 있습니다.
Memory grant persistence
쿼리에게 부여되는 메모리 크기는 실행 계획과 함께 Plan Cache에 저장이 됩니다 그런데 SQL Server의 메모리 압박으로 인해 Cache 정보가 제거되거나 혹은 이중화 환경에서 Standby 서버로 Failover 되는 등의 상황에서는 결국 해당 정보가 초기화 되어서 앞서 다룬 추정 메모리 크기 오차 문제가 재발된다는 것입니다.
이를 해결하기 위해 SQL Server 2022에서는 쿼리 저장소(Query Store)를 이용합니다. 쿼리 저장소는 파일에 영구적으로 보관되고 Standby 서버와도 동기화가 되므로 위와 같은 문제를 보완할 수 있게 되겠죠, 물론 쿼리 저장소 기능을 사용한다는 전제가 필요해서 SQL Server 2022부터는 신규 생성되는 DB(또는 Azure SQL 환경)에서 기본값으로 설정되어집니다.
따라서 SQL Server 버전을 업그레이드를 하는 경우에는 쿼리 저장소 기능을 사용할 것이지 여부도 중요하게 검토가 필요합니다. 실제로 사용한다면 그에 따른 테스트와 모니터링도 중요하겠죠? 특히 대형 시스템이나 사용량이 많은 DB라면 더더욱.
Percentile grant feedback
매개변수 쿼리나 저장 프로시저처럼 초기 생성된 실행 계획을 반복적으로 재사용하는 경우에 흔히 말하는 “실행계획 재사용 부작용”이 발생할 수 있죠. 예를 들어 입력 매개수 값이나 내부 로직에 따라 실행 시 행 수의 큰 차이가 발생하는 경우라면 그에 맞는 쿼리 실행 메모리가 부여되어야하는데 처음 한 번 계산된 메모리를 정적으로 계산 부여하게 되므로 문제가 발생할 수 있는 겁니다.(위에 소개한 MS 문서에서 부여되는 메모리가 마치 톱니바뀌처럼 들쑥날쑥함을 나타내는 이미지가 있음)
이를 해결하기 위해 SQL Server 2022에서는 시계열 데이터 분석에서 다루는 일명 “평활화(smoothing)” 기법을 적용합니다, 주식 경험자라면 주가 차트에서 이동평균선을 생각하면 됩니다. (주식투자자 여러분 모두 화이팅^^) 말 그대로 오르락 내리락 변동이 심한 구간에 이동평균 또는 기타 여러가지 계산법을 이용해서 보다 평평하게(매끄럽게) 이동하는 구간으로 변환하는 것입니다. SQL Server에는 “Percentile-based calculation”을 사용한다고 소개합니다.
정리
저는 개인적으로(또는 제가 속한 회사에서는) 아직 SQL Server 2022 (정확히는 Enterprise Edition을 사용하는)를 사용하는 고객사와 시스템을 경험해 보지 못한 관계로 이러한 변화들이 실제 어떤 영향을 미칠지 확인해 보지 못했습니다만, DBA 또는 관리자 입장에서는 분명 이전에 알지 못했거나 대응하기 어려웠던 복잡하고 내부적인 처리들을 어느 정도 자동화된 방식으로 처리되어가는 변환들에서 많은 도움을 받을 수 있을 것이라 생각됩니다 기업 입장에서도 마찬가지구요.
앞으로 계속 지켜보면서 업데이트가 있으면 다시 또 여러 경로로 공유하겠습니다.
모두 건강하세요.
김정선 드림
