

OLTP 쿼리만 사용되는 순수 OLTP 시스템이 아니라면 ERP, GW, MES, EMR 등의 대부분의 업무시스템들은 OLAP성 쿼리들(예를 들어 통계/집계성)이 존재하고 그에 따라 쿼리가 병렬로 처리되는 경우는 일상적으로 발생합니다. 일반적으로 쿼리 실행 시 다양한 형태의 리소스 대기(예를 들어 잠금, I/O 등)가 발생할 수 있는데 병렬연산에서 대기가 발생하는 경우 나타나는 리소스 대기 이름이 “CXPACKET”이었습니다.
현재 미국에서 SQL Server 컨설팅 회사를 운영 중이며 이전에 Microsoft SQL Server 개발팀의 멤버였던 Paul Randal이 2016년에 Microsoft에 제안을 합니다, CXPACKET 대기를 두 가지 유형으로 분리해 달라는 것이었습니다. 기존 CXPACKET을 다시 CXCONSUMER + CXPACKET으로 나누는 것입니다. Microsoft 개발팀은 이를 수용했고 SQL Server 2016버전부터 새로운 병렬처리 대기 유형을 보게 되었습니다. 그럼 CXCONSUMER는 무엇이고 어떻게 달라진 것인가? 이제 SQL Server 2016/2017/2019를 사용하는 고객사가 많아진 만큼 간단하게라도 소개가 필요하다고 생각되어 이번 글을 준비하게 되었습니다.
병렬처리 대기
아래 그림은 실제 사이트에서 수집된 리소스 대기 (일정시간 누적된) 통계 정보로서, CXPACKET과 CXCONSUMER 라는 이름의 대기 유형이 누적 순위 상위에 있는 것을 볼 수 있습니다. 평균적으로 추정하면 실제론 상위 5위 내에 있는 경우가 대부분입니다, 그 만큼 리소스 부하량이나 쿼리 성능에 있어서 많은 영향을 미칩니다.
참고, 아래와 같은 정보는 sys.dm_os_wait_stats 를 이용해서 볼 수 있습니다.
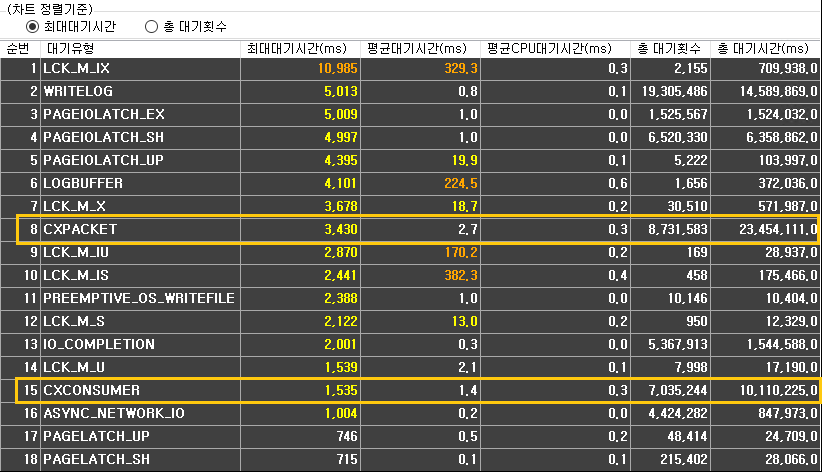
CXCONSUMER와 CXPACKET 대기
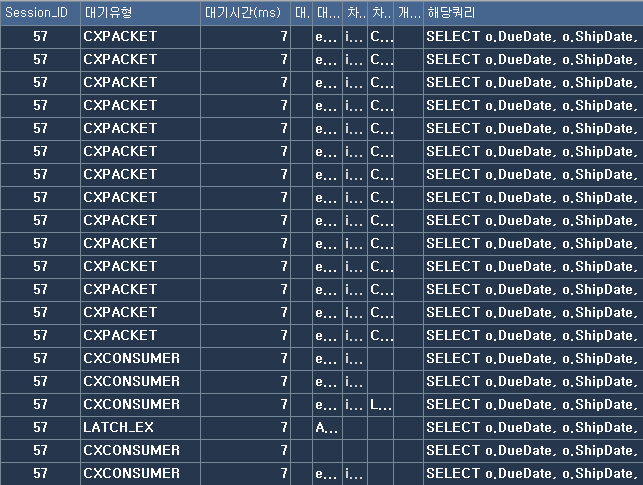
쿼리가 병렬로 처리되는 경우 아래 그림(데모로 재현)과 같이 CXPACKET 대기와 CXCONSUMER라는 이름의 대기가 발생하는 것을 볼 수 있습니다. 이는 병렬처리를 위한 자연스러운 결과물이지만 그 대기시간이 허용하기 어려운 수준을 넘어선다면 해당 쿼리의 응답속도나 시스템 부하에 상당한 영향을 끼치게 됩니다, 따라서 필요한 경우 튜닝을 해야죠.
참고, 아래와 같은 정보는 sys.dm_os_waiting_tasks에서 볼 수 있습니다.
해당 쿼리의 실행계획을 출력하면 연산자들(아이콘) 중 병렬처리(Parallelism) 관련 연산자들을 볼 수 있습니다. 여기서 발생하는 대기가 바로 CXPACKET입니다. Paul Randal의 의견은 이러한 병렬처리 대기에서 정상적이라고 볼 수 있는 작업과 병렬 처리 자체 대기 즉 튜닝이 가능한 유형으로 나누자는 것입니다.
참고, 병렬처리 연산자를 포함한 전체 연산자들의 설명을 여기에서 볼 수 있습니다.
쿼리 실행계획이 보이는 연산자들에게는 자신에게 데이터를 입력해주는 연산자(일명 Producer)와 해당 데이터를 소비하는 연산자(일명 Consumer)로 나누어 볼 수 있습니다. 아래 그림을 예로 들자면 Parallelism 연산자가 Consumer이고 Merge Join이 Producer에 해당하는 것이죠.

그렇다면 Parallelism 연산자가 자신의 연산을 수행하기 위해서는 Merge Join에서 제공하는 데이터가 입력되기를 기다려야하겠죠, 이 때를 CXCONSUMER 대기라고 명명한 것입니다. 반대로 Parallelism 연산자가 내부 연산을 수행하는 동안에 발생하는 대기가 기존의 CXPACKET으로 표현되는 것입니다. (참고, 지금까지는 저희 이해를 바탕으로 한 설명입니다 혹시 다르거나 틀릴 수도 있습니다^^)
병렬쿼리 튜닝
위 설명을 기준으로 하자면 CXCONSUMER 대기를 선행 연산자의 처리 성능에 따르는 것이므로 이 대기가 대량으로 발생할 때는 선행 연산자 처리에 튜닝이 필요할 것이며 Parallelism 연산자 자체 이슈가 아닌 것이죠.
반대로 CXPACKET 연산자는 자체 연산 과정에서 대기가 발생하는 것이므로 여기서 대량의 대기가 발생한다면 튜닝 대상이 될 수 있다고 볼 수 있습니다. 이럴 때 우리가 수행할 수 있는 일반적인 접근이 바로 MAXDOP 옵션을 하향 조정하거나 불균등 분포를 가진 통계를 조정하거나 쿼리 자체를 튜닝하는 등의 다양한 방법을 적용하는 것입니다, 물론 원인 분석이 먼저겠죠.
마무리
이제 차이점이 이해가 되셨나요? 저는 처음에 이 내용을 접하고 고개를 갸우뚱했습니다, 뭐지? 이렇게요^^
병렬쿼리나 병렬처리는 적재적소에 활용되면 그 만큼 쿼리 응답속도 향상이나 시스템 성능에 도움이 되지만 그 반대의 경우엔 오히려 저해 요소가 될 수 있습니다. 그 중에 하나가 병렬처리 리소스 대기입니다. Microsoft SQL Server는 병렬처리 대기에 대한 보다 상세한 분류 정보와 추가 메타 데이터들을 제공하므로 이를 잘 활용하면 쿼리 성능 튜닝이나 시스템 안정화에 많은 도움을 얻을 수 있을 것입니다.
CXCONSUMER와 CXPACKET 대기에 대한 보다 자세한 설명과 성능 튜닝 방법들에 대한 자료들이 많이 있습니다, Google 검색을 통해서 더 많이 학습해 보세요 😀
